
At Microsoft Sports, we have been building a distributed low-latency data and UX infrastructure in Azure. We power experiences used by millions of people daily across Windows, Bing, MSN, Office, and other Microsoft products. This blog post describes our overall approach, and, more importantly, shares tips and tricks that we learned while building a distributed Azure based system.
Table of Contents
- Overall Approach and Philosophy
- Data Flow
- Tips on Building a Distributed System in Azure
Overall Approach and Philosophy
Goals
- Low latency: Minimize the amount of time between receiving updated sports information and displaying it to users across all Microsoft properties (target: 1 second). For example, when some player stats update we want to reflect this change as fast as possible to all of our users.
- Event based: Instead of having the modules in our infrastructure each pull data, we want to ensure that as soon as new information enters the system, it cascades through push events across the entire stack. This goal reduces resource usage and also contributes to the previous goal of minimizing latency. We explain these benefits in more detail further on in this document.
- Reusable UX: Develop the UX once and show it in a consistent way across multiple canvases and form factors, instead of reimplementing it in the code base of each product. When you multiply the number of products, with the number of form factors, and the number of user scenarios together you get hundreds of combinations, which gets overwhelming quickly. Therefore, reusing UX is vital. Also, onboarding new developers is much easier when they have to learn a single code base as opposed to learning the disparate code bases of multiple Microsoft products.
- Agility: Check in and deploy code (to production if needed!) in less than 10 minutes, across all properties where sports data gets displayed. This allows us to speed up development of new features, fix bugs quickly, and reduce the time to mitigate outages.
- Debuggability: Log everything about how sports data travels in the system, centralize log collection, allow searching new logs with a delay of at most 5 minutes, and enable the seamless creation of dashboards and alerts.
- Scalability: Ensure the infrastructure is distributed and can scale across clusters of machines to support future growth, such as adding more data providers, UX canvases, and API partners.
- Common schema: Abstract away differences between upstream data provider schemas by converting all raw data into a single common Microsoft Sports schema. The main advantage is that we can then change data providers without rewriting the UX, since the user interface is built to use our common schema.
Technology stack
- C#: Our code is written in C#, using .Net Core 3.0, and soon, .NET 5.0.
- Azure Blob Storage: We store 7 TB of raw data, covering decades and sometimes, depending on the league, more than a century of sports information. We also use blob storage to store intermediary data that is used between data processing steps, and to cache database query results. When we use blobs for caching database results, we achieve a hit rate of 80%, which saves millions of database calls per month. In total, across the entire storage account, we perform 1 billion transactions (reads and writes) on blobs monthly.
- Azure Queues: Parts of our data processing pipeline are linked together by queues. Due to their nature, each queue can have a single function consumer. However, a particular queued triggered Azure Function can have multiple instances, so multiple queue items are processed in parallel. We execute approximately 30.5 billion queue transactions every month.
- Azure Event Grid: While having a single consumer function per queue is appropriate for the data ingestion steps, UX generation requires a one-to-many approach, as for example if the statistics for a player update, we need to regenerate the UX for the player across multiple canvases. A single data update needs to be able to trigger multiple separate UX functions. Therefore, we also use Event Grid, which is one-to-many. We send out about 14 million events monthly.
- Azure Functions: We use a so-called serverless architecture that actually runs, depending on load, on up to 300 machines in parallel. Our business logic is split into small Azure Functions, which consist of C# functions that have one input and zero or more outputs. The output of one function can be the input of another function. Data can travel from the output of one function to the input of another function using, for example, Azure Queues or Event Grid. Our developers do not concern themselves about where the functions run and how many instances of each function run in parallel. Instead, they follow a few basic requirements and mostly focus on the logic of the application, knowing that the application will correctly scale to hundreds of machines. For example, say we have one function that writes into a queue, and a second function which reads from the queue. If the first function writes 1000 items to the queue, the infrastructure can start multiple separate instances of the second function to process items from the queue in parallel. The instances of this second function run on multiple machines in the cluster. Developing microservices fits in our bigger aim to migrate from older monolithic code to a more modern architecture.
- Azure Cosmos DB: We chose this NoSQL database as our main storage because it is scalable, it has a good SLA, and it allows storing and querying complex JSON documents. On a typical month we issue more than 13 billion requests, the vast majority of which are read queries.
- Azure Pipelines: These pipelines help us test and deploy code in a timely manner. Every time we commit code to a new branch, we have one pipeline that builds the project and runs all the unit tests. A developer can merge their change into the main branch only if this pipeline successfully completes. Once the code is in main, a second pipeline automatically runs and deploys it to our test environment. After manually testing in the test environment, the developer can then go back to the pipeline and activate a manual gate to send the same package to the production environment. If we have any live site incidents the person on call can skip the test environment phase and directly deploy bugfixes to production. This setup allows us to be agile both in fixing bugs and writing new features. We usually deploy multiple times to production throughout the day.
- Application Insights: We are big fans of Application Insights, which collects and indexes our logs. From a single interface we can use intricate queries to search within the logs collected from all of our machines, we can generate graphs, and also set up alerts. Our machines generate 7 TB of logs per month, all of which are searchable within seconds.
- Azure Key Vault: We avoid storing secrets such as connection strings and API keys as clear text in our code repository. Instead, we follow security best practices and we store them inside Azure Key Vault.
- Azure API Management: Although we typically build the user interface across different products ourselves, there are some partner teams which prefer accessing the structured data directly. Azure API Management is a gateway which sits in front of our API serving machines, and handles user authentication, rate limiting, and geographic load balancing.
Data Flow
We have multiple external and internal sports data providers, each providing data through different ways (push, pull, HTTP, FTP, etc.) and with different schemas. Our system ingests these disparate data sources and converts them into a single common Microsoft Sports schema.
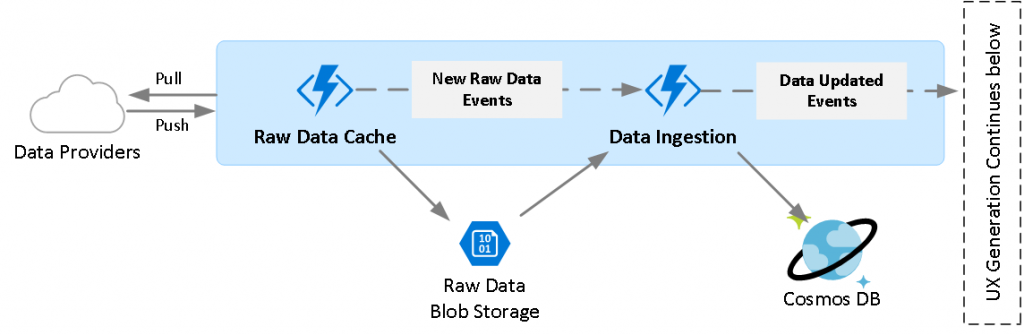
The figure above shows that happens once the raw data from our data providers enters our system:
- Raw Data Storage: The raw files get delivered to an Azure Function, which stores it to an Azure Storage account as individual blobs (files). The reason we store the raw data in this intermediary storage account is that once we have a copy of the data, subsequent modules in the system can access it multiple times without requiring more external requests to our data providers. In addition to storing the latest version of each file, this also allows us to keep a full history of all the versions of a file. Lastly, at this point we can compare the previous version of a file, with the new version, and notify downstream components to continue data processing only if the file has changed. This is shown as New Raw Data Events in the figure.
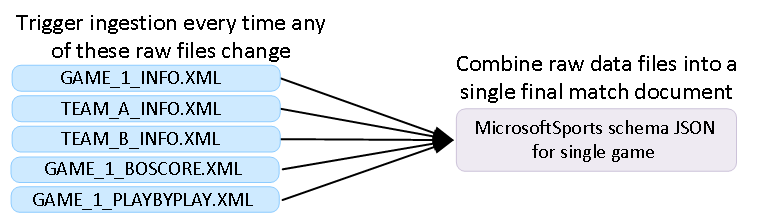
- Data Ingestion: This module combines raw files with heterogeneous schemas into homogenous entities that follow the common Microsoft Sports schema. To generate a single entity, for instance a game, we need to combine multiple raw files such as basic game information, play by play, commentary, translations, etc. This means that if any of these raw dependent files change, we trigger the regeneration of the entire game entity.
Before we store the new version of the game, we compare it with the old version previously stored in the database. Depending on which fields inside the entity changed during data ingestion, we emit specific events to rebuild only the UX submodules that are affected by the change (Data Updated Events in the figure below). For instance, if the game clock changed, we only want to update the UX submodules where the clock shows up, instead of refreshing all the UX for the game. The figure below shows the UX generation and API serving layers.
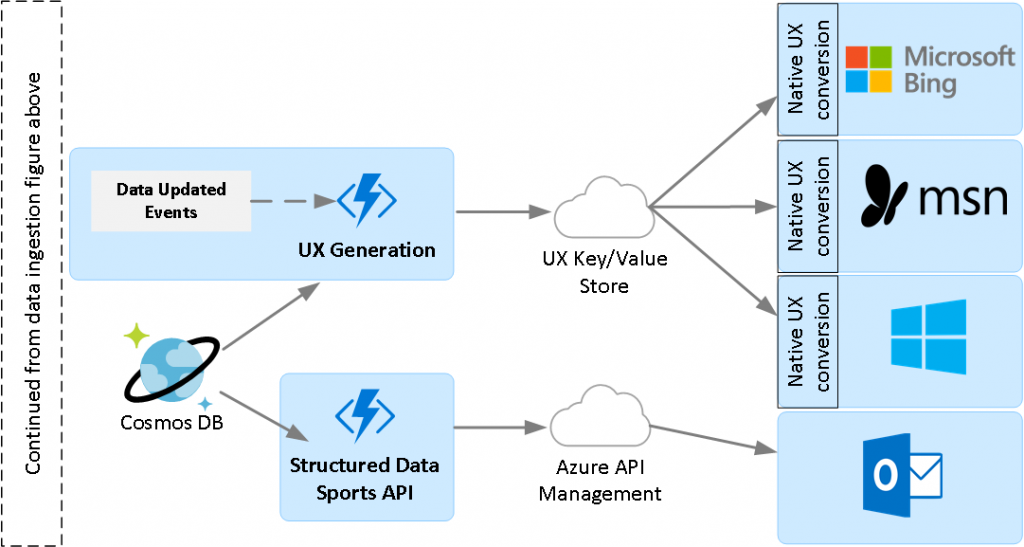
- UX Generation: Since we power multiple UX canvases across disparate products, we took a unique approach where we build our UX in a common language with generic UX controls, which then gets converted to the native UX controls of each product. For example, say we want to display a menu where the items represent weeks and below it show a list of NFL games scheduled for week 16 of games. We would express this in the common language, and then this gets converted to the native Bing menu control, the native MSN.com menu control, etc. This conversion happens mechanically in a thin layer that we write inside each product.
- UX Key/Value Store: One important aspect of our UX generation components is that we precompute all combinations of UX and store them as values in a key-value store. The key in the store contains the name of the scenario and other information to uniquely identify the specific UX. If we continue with the example above, imagine the key would look like NFL_Week16_Schedule and the value would contain the common UX language representation of the user interface. Now if a user visits Bing.com and they search for the query “nfl week 16”, we would map this query to this particular key, retrieve the value from the store, then render the result and show it to the user. Therefore, the important aspect to understand is that UX generation is not triggered by a user querying or going to a page, but is actually triggered by data change. By the time user goes to the page, the UX has already been generated for them and is already available in the key-value store.
- Structured Data API: Some of our partners consume our data in structured format instead of precomputed UX, therefore we also created an internal API to server this need.
Tips on Building a Distributed System in Azure
Building a prototype is simple. Scaling it to production traffic is much more difficult. Along the way had to overcome various limits and caveats in every Azure service that we use. Below we are sharing some of our experience so you can build better distributed systems and avoid some of our mistakes.
SNAT Port Exhaustion
The individual machines that are part of an Azure Functions cluster have private IP addresses and share a single public IP addresses for outgoing connections through a load balancer. When an instance makes an outbound connection, the load balancer uses network address translation to convert the internal traffic to external Internet traffic. Each machine receives a limited budget of outbound connections. Depending on the plan you choose, this number could be as low as 128 outbound connections per instance. If you do not use static/singleton clients, you will quickly run into the issue of SNAT port exhaustion. Make sure to closely follow the guidance provided by Azure Functions team on this topic, it will save you a lot of headache down the line.
To check if your app is impacted by this problem, click on Diagnose and Solve Problems, then search for the SNAT Port Exhaustion detector. Even if you follow the guidance on using singleton clients, you may find that your application can still reach SNAT port exhaustion. This can happen if your application crashes often and has to create connections, or if your application is under heavy load and is making a significant number of external requests. In addition to fixing the crashes, there are other ways to reduce SNAT port usage. Instead of making requests to services such as Cosmos DB over the Internet using a public IP address, you can use service endpoints and private endpoints to ensure the connections go over your virtual network and do not count against the SNAT port limit.
ARR Affinity
An Azure Function App is hosted in Azure App Service, and therefore it shares some of its configuration option. One such option is ARR Affinity. When this setting is on, the load balancer which distributes incoming requests to the underlying machines in the plan attempts to preserve state by trying to send subsequent traffic from the same client to the same machine. This is very problematic for repeating Event Grid traffic. Assume for example that there is a live basketball game and our data ingestion module keeps receiving new game information and sending out Event Grid events to our UX generation components. The way Event Grid works, data ingestion sends a message to Event Grid, and Event Grid then relays this signal to the UX functions by using HTTP POST. Since these messages go through the load balancer of the basketball UX app, if ARR Affinity is set to On, the load balancer will try to always send traffic destined to a basketball UX function to the same machine. This means a single machine will bear the brunt of most of the traffic, unless we turn off the setting. If ARR Affinity is turned off, the load balancer will randomly send traffic to any UX generation machine in the pool, and therefore the load will be distributed.
If you create a new Function App in the portal as of this writing in February 2021 the setting defaults to On. Make sure to go turn it off by going to Configuration > General Settings > ARR affinity: Off > Save.

Host restarts due to timeouts, memory usage, and lock contention
An Azure Function App is a collection of Azure Functions hosted together. Depending on which hosting plan one chooses, there typically is a maximum run time for each instance. If an instance of one of the functions in the app runs for too long and reaches the timeout threshold, the entire app and all the functions in it will get forcefully stopped on that machine, and a new instance of the app will start from scratch. It’s important to understand that if you have a bug in one of the functions, it could affect all of your other functions as the entire app gets restarted over and over.
There are other scenarios where the entire app gets restarted. It can also happen when the app instance runs out of memory, when there are lock contention issues, or when there are unhandled Exceptions that the Azure Functions host cannot catch on its own. There is an outer try-catch applied to your code by the host, so unhandled exceptions in your own code should typically not cause the app to restart. If the app instance gets restarted, it may take some time for it to be able to accept new traffic, such as incoming Event Grid events. If the same problems occurs in parallel across all of the machines in your app service plan, the entire app can become unresponsive. In the case of incoming events, this will show up as failures in the Event Grid log. To find how often your application gets restarted, which also happens when you deploy new code, start by searching for these substrings in the logs: ”Host is shutting down”, “Host started”, and “Host initialized”.
Avoid RunOnStartup timers
Azure Functions can be triggered by timers, which let you run functions on a schedule. In addition to their normal triggering schedule, timers can also start the function when the app starts, by setting the RunOnStartup parameter to be true. There are a couple of problems in doing so. First, all the functions with this parameter will start every time the host is initialized. If you have many such functions and/or your app restarts often due to deployments or crashes, this can generate heavy load on startup. Second, you need to be aware that these functions will run on each machine in the cluster. If you deploy code on 100 machines, each of them will run all of the triggers. Every such function will run 100 instances immediately. Therefore, avoid setting the RunOnStartup parameter to true.
Queue triggers can lead to high polling request rate
Whereas functions triggered by Event Grid use a push mechanism via incoming HTTP POST requests, functions triggered by Azure Queues instead use periodic polling to determine if there are items in the queue. The disadvantage of pulling items is that each queue triggered function in the app uses resources to periodically check its corresponding queue. In one of our apps we had hundreds of such functions that listened to queues. Because each function polls a distinct queue every few milliseconds, we easily reached the maximum request rate of 20,000 in the storage account used to store the queues. There are multiple ways to avoid this, including combining multiple related functions to use a single queue, using an alternate approach such as Event Grid, or increasing the polling interval by changing the maxPollingInterval setting in host.json. In the future the Azure Functions team may allow setting the polling interval per function, as opposed to once for the entire app.
Event Grid triggered functions do not set up subscriptions
At startup, the Azure Functions host creates empty queues for each function that listens to a queue. Therefore, developers do not need to manually create these queues, they can just input their name as a parameter of the trigger attribute and they will get automatically created. However, that is not the case with Event Grid triggered functions. In this case, there is no magic which sets up Event Grid subscriptions and links functions together. We instead had to create our own attribute called EventGridListenerSetup, which we place on top of functions that we want to trigger using Event Grid. At startup we use reflection to find these functions, then issue subscription creation commands to the Event Grid API.
Event Grid limits
When we initially started using Event Grid, we stored all of our subscriptions inside a single topic. A subscription corresponds to a single Azure Function triggered by an event. As our codebase grew, we eventually reached the limit of 500 subscriptions per standalone topic. To overcome this limit, we switched to using an Event Grid domain in which we split our subscriptions into multiple topics, by sport. This allowed us to have a 500 subscription limit for each sport such as football, baseball, etc. After some time we again started hitting the limit in each sport.
To further distribute the subscriptions, we decided that instead of using one topic per sport, we were going to use one topic per sport league. Therefore we split baseball into leagues such as MLB, NPB, KBO, etc. The moral of the story is that you should plan ahead and organize your subscriptions to stay within limits and to mimic your internal business organization.
Organizing code into apps, and apps into hosting plans
You can think of a dedicated App Service Plan as a cluster of machines. Each such app can run one or more apps. If multiple apps run on one plan, they all share the same underlying machines. Depending on the load of the apps, you may choose to run a single heavy app in a plan, or run multiple lighter apps in a single plan. In order to have this flexibility, one needs to split the code into smaller apps. In our case, we have one app for collecting data from our upstream data providers, one app per each sport for data ingestion, and finally one app per sport for UX generation.
Since the data ingestion modules use less resources than the UX generation components, we decided to host all data collection and data ingestion apps inside the same plan, while we created separate plans for each of the sports for UX generation. This code organization allows us to be flexible and grow with our usage. If in the future we start receiving a large amount of data for a particular sport, we can always just move that app to a separate plan. If the code would be organized in a single large app, that would be more difficult to do, and it would also be easier to hit scalability limits.
App Service plan differences and migrating between plans
As long as an application correctly uses the Azure Functions SDK, it can be hosted under multiple types of plans, without changes to the code. Each type of plan has its advantages, disadvantages, and costs. Once important consideration when choosing the plan is to know how well it can scale out. For some of our apps we use the dedicated plans, while for others we use Premium plans. The difference is that the former is limited to a maximum of 30 machines per app, while the latter can go up to 100 machines per app. If you are ever in the position of migrating an app from a Dedicated to a Premium plan, be aware that the Premium plan requires two extra settings to be configured: WEBSITE_CONTENTAZUREFILECONNECTIONSTRING and WEBSITE_CONTENTSHARE. If you do not set these settings, we have found that deployments to the Premium plan can silently fail.
Cosmos DB (Re)Partitioning
Cosmos DB is a highly scalable database, which gladly allows you to shoot yourself in the foot. Every item stored in a Cosmos DB collection, which is the equivalent of a table in other databases, requires a partition key. The database uses the partition key to colocate related data closer together on the underlying machines that make up the distributed data store. Having the partition key be a random string is a reasonable solution for some use cases, as this ensures a uniform distribution of the data across the underlying machines. However, that also means that every read query is then a cross-partition query, since the query planner needs to fan out requests to all machines. A better solution is to pick the value of the partition key to be a logical grouping of your data.
In our case we created a partition key that is a combination of sport, league, and season year. For instance, all data stored for the 2020 MLB season receives the same partition key value: Baseball_MLB_2020. Whenever we want to query for data from this season, we include SeasonId = ‘Baseball_MLB_2020’ in the WHERE clause of the query. Since all of our collections have the partition key set to SeasonId, the query gets routed to only the subset of machines which contain the data for this particular season. One last issue to note is that Cosmos DB collections cannot be repartitioned on the fly. Instead, one needs to create a new table with a different partition key, then copy the old data over. Therefore, be careful how you choose your partition key.
The consequences of increasing Cosmos DB limits
Cosmos DB usage is billed based on Request Units per second, which are a combination of CPU usage, input/output operations per second, and memory usage. Usage can scale to a maximum RUs you define and pay for. As your application grows, you may start increasing your maximum RU limit. If at some point you have a spike of traffic, you may even bump the maximum up significantly. However, be aware that this change has long term consequences. As you increase the limit, the data gets reorganized into more and more physical partitions, or shards. If at some point you bring the maximum limit back down, the number of physical partitions does not scale back down, it remains the same. At that point you may find that the cost of a cross-partition query becomes significantly higher than before since it gets served from more physical partitions, even if the query itself or the underlying data does not change.
Use delay in queue items
When we manually refresh an entire sports season of data, some functions can write a large amount of items into a queue. For instance if we refresh the UX for an entire season worth of MLB games, this can generate around 2,500 items, one for each game. Without taking precautions, the entire cluster can get overwhelmed by processing all of these items as fast as possible in parallel. We solve this issue by spacing out the items in the queue so they are processed more slowly. To achieve this, we gradually increase the visibility timeout of each message as we add them to the queue. We created an Azure Functions extension called Delayed Queue which automatically incrementing the visibility timeout for each queue item by a given number of milliseconds.
Forcing an older version of the Azure Functions runtime
Accidents happen. Very rarely you may find that a new version of the Azure Functions runtime has bug in it that prevents your application to successfully run. In that case, you can temporarily downgrade to a previous version by using the FUNCTIONS_EXTENSION_VERSION setting.
Use the latest Azure SDKs
In July 2019 Azure announced a modernization and unification of their client libraries for services such as Azure Storage, Cosmos DB, Key Vault etc. They decided that the new libraries were different enough that they had to publish new separate NuGet packages, while continuing to maintain the older libraries in their original locations. Many projects, including Azure Functions, internally still use the old libraries. However, most of the engineering effort has moved on to focus on the new libraries, which receive the most updates, performance, and scalability improvements. In our code base we now support both sets of libraries so we can continue to run older code while making the new libraries available for new features. Whenever you can, consider using the new packages.
Key Vault References in local.settings.json
As mentioned previously, we store our secrets in Azure Key Vault to avoid storing them as cleartext in our code repo. Although Azure Functions supports resolving Key Vault references when the code runs in Azure, that is not the case for local development. When debugging code locally, Azure Functions reads settings from the local.settings.json file. However, local Key Vault references are not yet supported. Due to our security policy we cannot store secrets as clear text, even if they are test secrets stored only in the local settings file. We have implemented a workaround for this problem ourselves, as did many other developers. We resolve the local Key Vault references in our code, and do not rely on the host doing that for us.
Deployment problems brought on by scale
Depending on how many sports events are live in a particular sport, our App Service environments sometimes auto-scale to their maximum (for example 30 machines in the dedicated App Service Plan). If we need to deploy new code in an environment that is under heavy load, deployments may fail due to timeouts or lock contention. We have been working with teams across Azure to resolve this problem and we expect that by the time you read this blog this will not be an issue anymore. Since our workload is spiky in nature we were affected by similar issues in the past in other Azure services. However, we were able to resolve them and make Azure better for all other customers.
Redis client library did not work for our needs
We spent weeks attempting to use Redis for caching database query results, but we had scaling problems due to the client library (not the Redis servers). When our Azure Functions machines were under load the Redis connections invariably started failing. We tried using the Azure hosted version of Redis, we tried installing Redis ourselves on beefy VMs, we contacted teams both internally and externally to help in debugging, but at the end of the day Redis simply did not work for us. We think the problem stems from the StackExchange.Redis client we were using, but we are not entirely sure. The solution was to abandon Redis and write our caching layer on top of Azure Blob Storage. Under the same load we were able to successfully achieve much higher throughput and we never had any connection issues.
Caching design and eviction policy
There are only two hard things in Computer Science: cache invalidation and naming things — Phil Karlton
We cache database queries to reduce load on Cosmos DB. We use a two-tier caching system where we first consult a local singleton MemoryCache that lives on each individual machine in the cluster. If we get a cache miss, we then proceed to issue a request to a central Azure blob storage based cache. Only of both caching layers yield a miss we issue a query to the live database. By default the entries in our cache have a time to live (TTL) of 30 minutes. This is reasonable for some types of entities such as teams and players which do not change often. However, this will not work for rapidly changing entities such as live matches. To cache live matches we take a slightly different approach. First, we bypass the local memory caches which can get out of sync, and only use the centralized blob cache. Second, at data ingestion time we overwrite the cache for the match before we send events to the UX generation component. This ensures that by the time UX tries to read the match, the centralized cache was already updated with the latest version of the game. While this approach works for individual entities, it does not work for groups of entities. Take for instance the schedule for a basketball league, which is made up of many different games. If any of the games in the schedule get updated, we want to also update the schedule, which is stored in a separate cache key. To solve this issue, we take yet a different approach where for every game in the schedule we create an empty pointer file that points back to the schedule. If any of the games update, our caching system also finds the pointer that points to the schedule key, which allows us to also invalidate the schedule cache. The result is that if any game in the schedule changes, it also triggers cache invalidation for the schedule. We take the same approach with any cached item which is made out of multiple entities.
Too many Azure functions
In this pipeline we are generating UX for multiple variations of properties such as Bing, MSN, Windows, API etc.; variations across canvas types such as desktop, mobile etc., as well as variations needed for A/B experimentation. Data ingestion notifies UX of changes using Azure Event Grid events. At this point UX gets generated and cached. We initially split the UX generation in separate Azure Functions for each such variation to make everything run in parallel. However, this approach backfired soon. Too many Azure Functions multiplied by bursts of events during live games caused the underlying VMs to get overloaded. Also since Azure Functions are stateless a massive number of executions started in parallel were multiplying resource usage e.g. Cosmos DB, data cache, UX cache. In these instances we easily hit resource usage bottlenecks and limits. At peak we had 1000+ Azure Functions distributed across a few apps. So we started optimizing: 1) We separated data models from UX and maximized reuse of data. 2) We used in memory cache more aggressively to avoid calls to Cosmos DB. 3) We published to the UX key/value store in batches to reduce SNAT port usage. Eventually we managed to reduce 1000+ functions to 130 functions. This also reduced our “out of memory exceptions”, “exception due to SNAT port exhaustion” etc. to next to nothing. Reducing total number function per app also made Azure Function apps more responsive in the Azure portal, for example if a developer wanted to list or run functions in the portal.
Another side effect of having too many functions is that the Azure Portal will be very slow or it will time out when listing the functions. This is stressful during outages if you cannot manually run functions to solve problems.
— Ovidiu Dan, Ramkrishna Khoso, Vaibhav Parikh, on behalf of the Microsoft Sports team


